
In this 30 minute video, we talk about Bias and Fairness in ML workflows:
- Why we need to handle fairness in ML models
- How biases typically creep into the ML pipeline
- How to measure these biases
- How to rectify the biases in our pipeline.
- A usecase with word embeddings
Click here to get the latest slidedeck.
Checkout my talk from MLOps – Fifth Elephant – HasGeek conference : How to build Fair and Unbiased ML Pipelines

Why care about fairness in ML ?
Biases often arise in automated workflows based on MachineLearning models due to erroneous assumptions made in the learning process. Examples of such biases involve societal biases such as gender bias, racial bias, age bias and so on. Lets look at some applications where bias can lead to unwanted outcomes.
- Lets say we are building a system for predicting loan eligibility. If gender is a feature of the model, with fewer female applicants having been approved, the model might learn that females are less eligible for a loan!
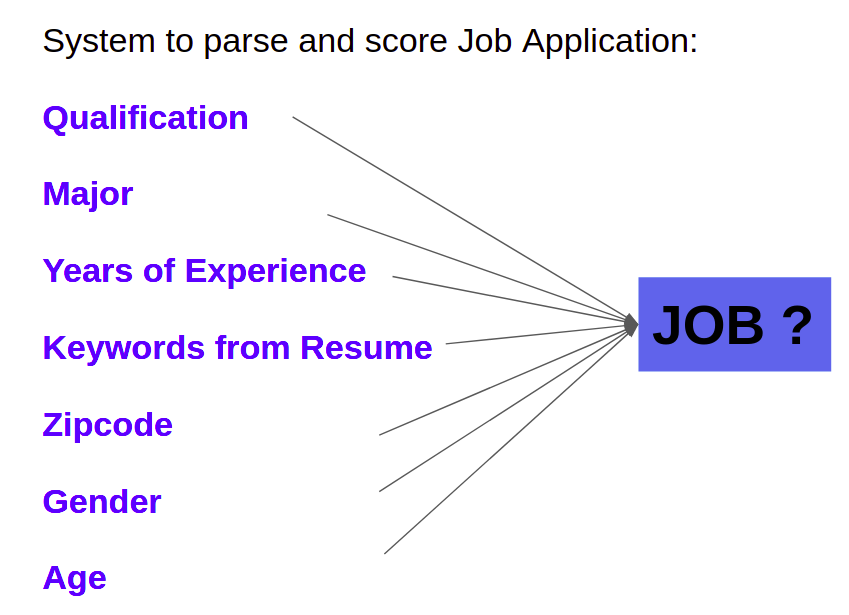
- Lets say we are building a system to shortlist job applications from an online form that collects various attributes such as years of experience, major, age, address with zipcode and so on. It is possible that the algorithm learns that people from certain zipcodes are less eligible for a job!
Bias and Fairness:
Historical Bias, Representation Bias., Measurement Bias., Evaluation Bias, Aggregation Bias, Population Bias, Simpson’s Paradox, Longitudinal Data Fallacy, Sampling Bias, Behavioral Bias, Content Production Bias, Linking Bias, Temporal Bias, Popularity Bias, Algorithmic Bias, User Interaction Bias, Presentation Bias., Ranking Bias, Social Bias, Emergent Bias, Self-Selection Bias, Omitted Variable Bias, Cause-Effect Bias, Observer Bias, Funding Bias……
There are many types of biases! For instance, training a model on time sensitive old data might not work well with newer data. This is a form of bias (temporal bias). Of we could talk about inductive bias that comes about when we introduce a regularization constant.
But not all are related to fairness.
When we talk about biases in the context of fairness, we are talking about socital biases that creep into our pipelines to cause unintended consequences.
Some examples of sensitve attributes that are related to such biases are : race, religion, gender, familial status, marital status, disability, age and so on.
How do biases end up in ML pipelines ?
There are many ways biases end up in ML pipelines. The following are five popular ways.
- Specification Bias: Bias that arises from model design – due to bad design of inputs or outputs for instance. The simplest example of specification bias is where you use features such as gender, age and race in the ML model where they are not needed.
- Sampling Bias: Typically arises when we do not sample from all subgroups. For instance, not sampling enough applicants from a certain major could cause a resume screening system to learn that some majors lead to higher job success than others.
- Measurement Bias: Arises from faulty measurements either from defective equipment or through incorrect recording of responses – for instance from a survey form.
- Lets say we are collecting data for covid response to understand the correlation between interventions and symptom progression. Having an option for “high fever/ low fever/ no fever” for the fever symptom could lead to garbage if many people are filling the form for their friends and family and do not remeber the exact seriousness of the symptom. It is important to have an option of “I dont know” !
- Annotator/ Label Biases: Biases can creep in from real world and lead to bad labels:
- Human biases could creep in from biased decisions in real world and we might have baised labels. For instance, there might be more loans approved for males than females due to a biased decision maker. These biases percolate into the data.
- Human annotator could be biased when creating labeled data. It is important to educate the annonators during label creation.
- Inherited Biases from other ML models : Input to ML models often come from other models. If we have a biased model whose output is fed into another model, we would end up with a biased outcome.
- A popular example is the word embeddings like word2Vec that are used as inputs for many NLP tasks. Word embeddings are known to have many inherant biases. These biases could percolate into the models where the embeddings serve as inputs.
How to measure biases in ML pipelines?
The way to measure biases depends on the specific application under consideration.
Popular metrics for measuring bias in the classification context are based on the confusion matrix. Examples of metrics that are explained in more detail in the above video and article include:
- Equal opportunity: Is the TPR same across different groups?
- Equalized odds: Is TPR and FPR same across different groups?
- Demographic parity: Likelihood of being classified positive same for protected vs non protected class
Whatever metrics are used, it is important to measure these metrics on an on-going basis as a part of the pipeline and not as a one-time effort.
How do we fix the biases in ML pipelines?
Fixing biases in ML pipelines could be based on a
- Pre-processing approach: We fix the input data to remove some of the biases by fixing issues with dataset design/ data collection process/ sampling and so on. For instance if there are fewer data points from a particular group, we can sub sample from other groups so that there is uniform sampling across protected groups.
- In-Processing: These approches involve designing the objective function such that there are additional constraints based on parity of metrics across protected groups.
- Post-Processing: This involves coming up with algorithms for fair decision making leveraging the outcome of the biased-ML model.
- Example implementing different thresholds for subgroups when we use a threshold based classification algorithm like logistic regression.
- Another example is debiasing word embeddings trained from skipgram model that is discussed more in the next section.
Usecase: Debiasing word embeddings
Refer to this video and article that talks more about debiasing word embeddings.
Word embeddings such as word2vec and glove are widely used as inputs to many NLP tasks.
They are great as features for NLP tasks since they come up with vector representation of word that preserve semantic similarity. In other words, words that are similar in meaning have embeddings that are close to each other in direction.

Another interesting aspect of word embeddings is that they preserve vector arithmetic from a semantic perspective.
- For instance Queen – King is in the same direction as Man – Woman
- Similarly Tokyo-Japan is in the same direction as Paris-France
Using this property, analogies such as the above (Paris:France :: Tokyo: Japan) can be generated from these word embeddings.
However, an unintended consequence is that there are many gender biased embeddings.
Example: He: Carpentry :: She: Sweing

These embeddings can be debiased. Look at my video and article that summarizes a paper on debiasing word embeddings for more details.
References: Bias and Fairness in ML Models
There are many papers that are reasonably easy to read that summarize the various challenges with fairness in ML, ways biases creep in and ways to deal with them. Here are a few popular ones:
https://arxiv.org/abs/2010.04053 Fairness in Machine Learning: A Survey: Simon Caton, Christian Haas, Oct 2020
https://arxiv.org/pdf/1908.09635.pdf A Survey on Bias and Fairness in Machine Learning, Mehrabi et al. Sep 2019
https://dl.acm.org/doi/10.1145/3209581 Bias on the web, Ricardo Baeza-Yates, Communications of ACM, June 2018
https://arxiv.org/abs/1607.06520 Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings, Tolga Bolukbasi et al, NIPS 2016
Other Software/ Links on Bias and Fairness in ML
https://github.com/fairlearn/fairlearn FairLearn / FATE https://www.microsoft.com/en-us/research/theme/fate/#!downloads
http://research.google.com/bigpicture/attacking-discrimination-in-ml/
https://engineering.linkedin.com/blog/2020/lift-addressing-bias-in-large-scale-ai-applications: Linkedin Fairness Toolkit: Addressing Bias in Large-Scale ML applications.