
This brief video describes the BLEU score, a popular evaluation metric used for sevaral tasks such as machine translation, text summarization and so on.
What is BLEU Score?
BLEU stands for Bilingual evaluation Understudy.
It is a metric used to evaluate the quality of machine generated text by comparing it with a reference text that is supposed to be generated.
Usually, the reference text is generated by a manual evaluator or a translator.
Where is BLEU Score used?
BLEU score was traditionally used to evaluate machine translation. Hence the Bilingual. (Note: Take a look at our article on a brief history of machine translation, that quickly summarizes various models used for machine translation)
However it is now used in a variety of NLP tasks that include text generation: some of which include
- Text summarization: Evaluate how well the generated summary matches a reference summary by a human expert.
- Image captioning: Evaluate how well generated caption matches with a reference caption generated by human
- Machine Translation: Evaluate how well the model generated translation matches with the reference translation.
- Speech Recognition: Evaluate how well the generated transcript matches with the reference text for the speech.
How to compute BLEU score?
The basic idea involves computing the precision – which is the fraction of candidate words in reference.


Clipping the count:
For each word in the candidate, clip the count to the maximum occurances in the reference sentence.
For the above example, the value of m is clipped to 2. Hence the modified precision is 2/7 which better reflects the quality of the translation.
BLEU Score with n-grams:
The above computation takes into account individual words or unigrams of candidate that occur in target.
However, for a more accurate evaluation of the match, one could compute bi-grams or even tri-grams and average the score obtained from various n-grams to compute the overall BLEU score.
For instance consider the following example.
Candidate sentence: The the cat.
Reference Sentence: The cat is on the mat.
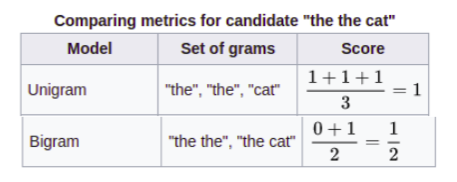
To compute the BLEU score for the entire corpus, one can compute the BLEU score for individual candidates with their references for each query sentence in the dataset and take an average.
What are the problems with BLEU score?
BLEU score is the most popular metric for machine translation. However, there are sevaral shortcomings of BLEU score.
- BLEU score is more precision based than recalled. So while it captures the fraction of candidate words in reference, it does not look at recall. In other words, it does not focus on whether all words of reference are covered by the candidate.
- BLEU score cannot handle semantic similarity. In computing the score, the algorithm is looking for exact matches, both for unigrams or n-grams. Often it is acceptable to use semantically similar words to convey the essence of the reference. For instance, “the cat is on the mat” should be close to “the cat is over the mat”. While “the cat is under the mat” means something completely different. BLEU score cannot capture this.
- While BLEU score takes into account groups of words repeating to some extent, by using n-grams, it is not great with capturing chunks of words of candidate that map to chunks of reference words.
A popular alternative for BLEU score that addresses these issues is the METEOR metric. Check out this article on the METEOR metric for evaluating machine generated text.
Code for BLEU Score
BLEU score is available to plugin from NLTK.
from nltk.translate.bleu_score import sentence_bleu
reference = [[‘this’, ‘is’, ‘a’, score’], [‘this’, ‘is’ ‘bleu’,’score’]]
candidate = [‘this’, ‘is’, ‘a’, ‘bleu’,’score’]
score = sentence_bleu(reference, candidate)
print(score)