
This short video describes METEOR, a metric for evaluating machine generated text.
It is used to evaluate whether the candidate text generated by an ML model matches the reference text (that is supposed to be generated).
Where is the METEOR metric used?
Meteor metric was primarily used in the Machine Translation literature. Checkout our article giving an overview of techniques for machine translation to get a better understanding of the translation application.
However, it is now used in sevaral tasks involving text generation such as text summarization, image captioning, speech recognition and so on.
Why do we need the METEOR metric?
BLEU score is the most popular metric for machine translation. Check out our article on the BLEU score for evaluating machine generated text.
However, there are sevaral shortcomings of BLEU score.
- BLEU score is more precision based than recalled. In other words, it is based on evaluating whether all words in the generated candidate are in the reference that a manual evaluator comes up with. But it does not check if all words in reference are covered!
- BLEU score does not take into account semantic similarity. The BLEU score looks for exact word matches. But it does not consider the fact that a word such as red is close to the word scarlet for instance. For example, “the cat is on the mat” should be semantically similar to “the cat is over the mat”. However “the cat is under the mat” does not mean hte same thing! BLEU score fails here.
- Good matches often have clusters of words in candidate that match closely with clusters of words in the reference. BLEU score is not great with capturing this.
How is the METEOR metric computed?
Here is the steps to compute the METEOR metric.
Computing an Alighment
An alignment between the generated text and the reference can be done by matching word for word, or by using tools for similarity such as word embeddings, dictionary and so on.
A chunk in an alignment is an adjacent set of words that map to adjacent set of words in the reference. The above alignment has three chunks.
While there are multiple alignments possible we want to pick that alignment where the number of chunks is the lowest.
For instance, take two sentences, “the cat likes the bone” (generated text) and “the cat loves the bone” (Reference). The word “the” in the gnerated text can be mapped to either of the two “the”s in the reference, but mapping it to the first makes more sense since it leads to just one chunk since all words in generated text map to reference consecutively: The – The, cat – cat, likes – loves, the – the, bone -bone.
Computing the F-score
METEOR takes into account both the precision and recall while evaluating a match.
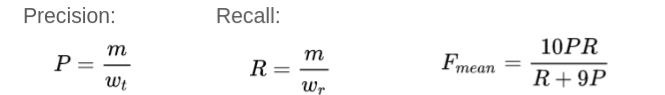
m: Number of unigrams in the candidate translation also found in reference
w_t: Number of unigrams in candidate translation
w_r: Number of unigrams in reference translation
Take a look at the following example:
Since all words of candidates are in the reference and all words of reference are in the candidate, we get a perfect score of 1 with the above definition based on the F score.
Computing Chunk Penalty
A chunk is a set of consecutive words. Typically we note that chunks of words in the source map to chunks of words in the target. The chunk penalty gives a penalty based on the number of chunks in candidate that map to chunks in target or the reference.
In an ideal case, if the candidate and the reference are the same, all words in candidate map to all words in reference consecutively and we just have one chunk. But in reality, we have more chunks in a less than ideal match.
The chunk penalty is computed as follows.
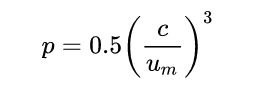
C: Number of chunks in candidate
U_m: Unigrams in candidate
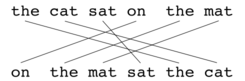
Once again consider an example with the following alighment:
There are three distinct chunks in the candidate (“the cat”, “sat”, “on the mat”) that map to different chunks in the reference. While there are six unigrams in the candidate. Hence, C is 3 and U_m is 6 to compute the formula above.
Computing the overall METEOR score
The final meteor score combines the F-score computed from precision and recall with the chunk penalty.
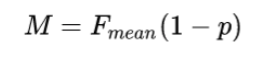
Hence, while the set of words in the reference and candidate are the same, in this example, we see a chunk penalty. This penalty ensures that “on the cat sat the mat” which matches perfectly with the reference (just 1 chunk) gets a higher score than “the cat sat on the mat”.