Unlike the popular notion that being involved with ML products involves crunching math and stats, there are a lot of steps involved in productionizing ML and creating real products.
Here is a brief video that explores Machine Learning Product development lifecycle and also talks about how it is different from the traditional product development lifecycle.
Top takeaways from this video:
- The Machine Learning product lifecycle is a very iterative process
- Make models as simple as you can, but no simpler
- Measure the right metrics to create real impact
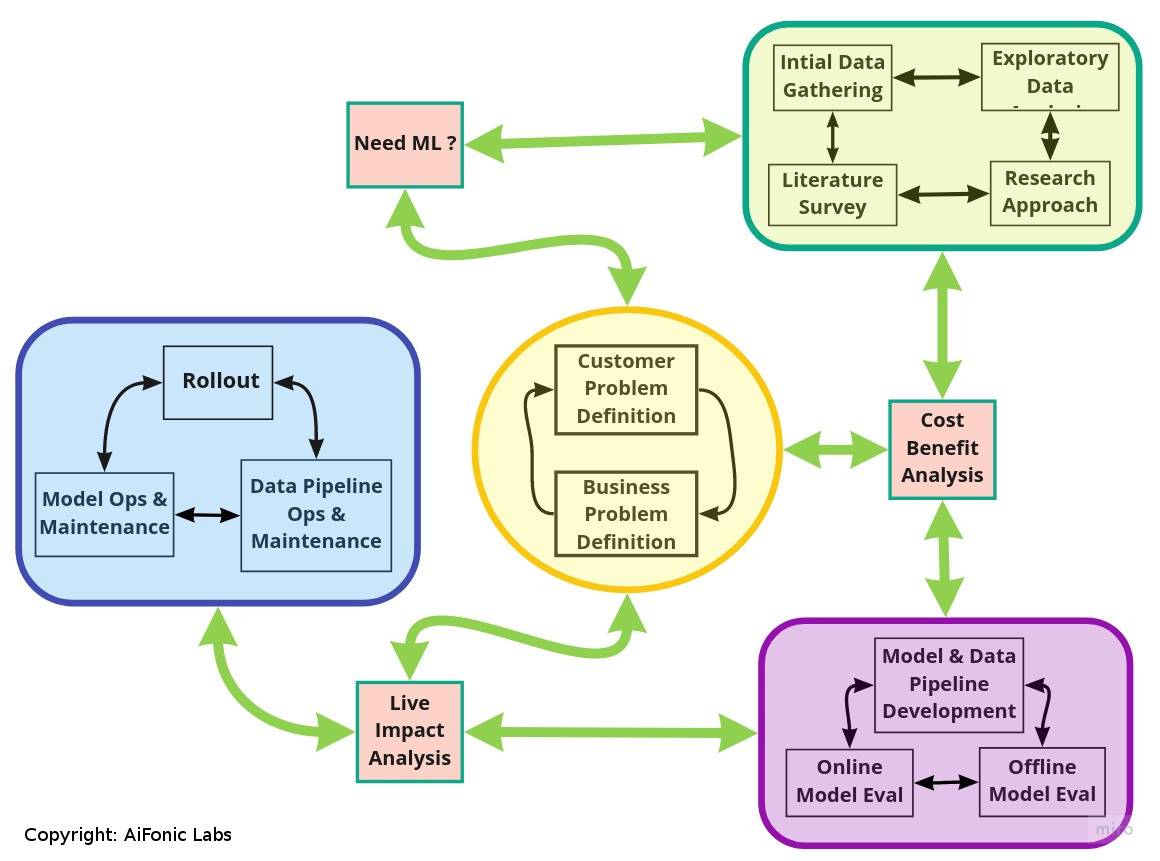
What are the steps involved in the Machine Learning Product Lifecycle ?
- Problem Definition: Understanding the customer problem and the business problem, defining success metrics
- Data Gathering: Gathering sample data and analyzing feasibility and challenges from a data perspective
- Exploratory Data Analysis: Come up with insights in data that can lead to potential solutions. Involves analyzing and visualizing data – sometimes also involves building a strawman model to understand the feasibility of solving the problem.
- Literature Survey: Involves understanding existing approaches to solve the problem, models used and how well they worked.
- Design ML and Engg Approach + feasibility analysis: Make a plan of what ML models are feasible to build to solve the problem and the engineering effort required to build the supporting pipeline including the data pipeline. Important to estimate the cost involved in terms of dev cycles and data scientist cycles. Also important to define the ML metrics that will be used with each of the proposed models.
- Model and Pipeline Development: Developing and debugging models and building supporting engineering infrastructure. This step also invloves tuning the model including finding the right hyper-parameters. This phase of the lifecycle can follow agile or scrum methodology as appropriate if it involves on-going interaction with stake holders.
- Offline Evaluation: It is important to try and see how much the developed solution improves the defined business metrics before trying it on actual customers. While it is hard to get an accurate estimate, it is useful to consider ways of simulating customer behaviour or A/B tests to get an idea how the model is likely to perform online.
- Online Evaluation + live impact analysis: Usually involves A/B testing and impact analysis per the defined success metrics. Might take a while for the test to reach significance.
- Model Rollout: If the model does well in terms of success metrics in the live testing phase, roll out involves pushing model to the larger audience – perhaps different geographies, categories or customer segments. This might involve some additional testing to ensure the model generalizes to other customer segments.
- Maintainence: Involves defining operational procedure in terms of who owns which piece of software from a support perspective, ensurung proper monitoring and logging, ongoing bug fixes and eventually model improvements.
 How is the Machine Learning Product Lifecycle Different from the traditional SDLC ?
How is the Machine Learning Product Lifecycle Different from the traditional SDLC ?
The machine learning product lifecycle involves risks that could be different from the standard SDLC. In the standard SDLC, with thorough design, implementing and testing the software is a relatively deterministic process. With data science, it is hard to say determininstically whether a model will work well and get the desired impact on real data without actually rolling it out.
But this risk can be mitigated by following good practices in the lifecycle and measuring the analyzing the right metrics throughout the process – to ensure we constantly make progress.
Who are typically the stakeholders in the Machine Learning Product Lifecycle ?
The possible stakeholders in the ML product lifecycle are the product manager, the engineering manager, the data scientists, the data engineer, software developer and a software architect. The team working on an ML project could depend on the size of the organization, reporting structure and various other factors – where multiple of the above roles can be merged into one. For instance, smaller organizations might not have a separate data scientist and a data engineer. In an early stage startup, the role of a data scientist, SDE and a data engineer might be merged into one.