
This video describes target encoding for categorical features, that is more effecient and more effective in several usecases than the popular one-hot encoding.
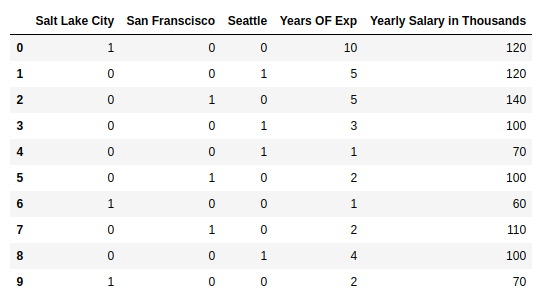
Recap: Categorical Features and One-hot encoding
Categorical features are variables that take one of discrete values. For instance: color that could take one of {red, blue, green} or city that can take one of {Salt Lake City, Seattle, San Franscisco}.
The most common way of representing categorical features is one-hot encoding. See the following picture for a one-hot encoded city feature.
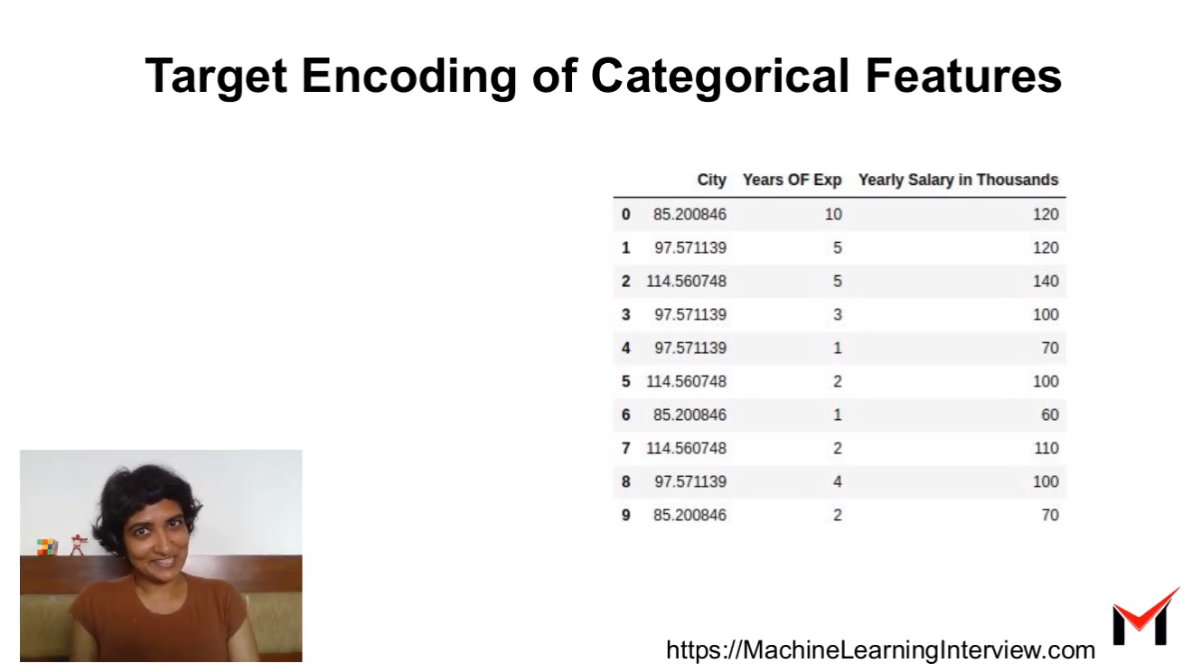
What is Target Encoding?
Target encoding involves replacing a categorical feature with average target value of all data points belonging to the category. For instance, Seattle can be replaced with average of salary (target variable) of all datapoints where city is Seattle.
An example of target encoding is shown in the picture below:

Overfitting with Target Encoding: Smoothing
One of the challenges with Target Encoding is overfitting. Some folks also refer to this as Leakage of target variable into one of the features. In these cases, the model with target encoding does not generalize well to new data.
There are sevaral techniques to reduce overfitting with target encoding, here are two of the popular techniques.
Leave-One-Out Target Encoding
Leave One Out Target Encoding involves taking the mean target value of all data points in the category except the current row. For instance, to fill Seattle in row 3, one would take the average salary in Seattle from all datapoints except row 3.
Leave One fold out Target Encoding is an extension of Leave One Out target encoding where instead of taking agerage target value of all datapoints belonging to current category except the current row, we leave out the current fold.
In other words, target values from all data points are averaged except the points in the fold belonging to the current data point. Both these techniques ensure that everytime a particular category appears we dont end up with the same value.
Smoothing for Target Encoding
One popular smoothing technique is to take a combination of the target for the category and the global target mean for each data point. This technique is particularly useful to handle situations when there are very few datapoints for some of the categories.
Adding Gaussian Noise
Adding some random gaussian noise to the column for each data point after target encoding the feature is another popular way of handling the overfitting issue.
When to use Target Encoding
- When you have many categories, good to use target encoding over one-hot
- Target encoding cannot capture dependencies between different categorical features
Example: Salary | city=Seattle, college=Seattle Central College > . Salary | city=Salt Lake or SFO, college= Seattle Central College
Python Code for Target Encoding
Target encoding can be implemented using the library category_encoders. See code snippete below for a working example.
import pandas as pd;
data = [['Salt Lake City', 10, 120], ['Seattle', 5, 120], ['San Franscisco', 5, 140],
['Seattle', 3, 100], ['Seattle', 1, 70], ['San Franscisco', 2, 100],['Salt Lake City', 1, 60],
['San Franscisco', 2, 110], ['Seattle', 4, 100],['Salt Lake City', 2, 70] ]
df = pd.DataFrame(data, columns = ['City', 'Years OF Exp','Yearly Salary in Thousands'])
df
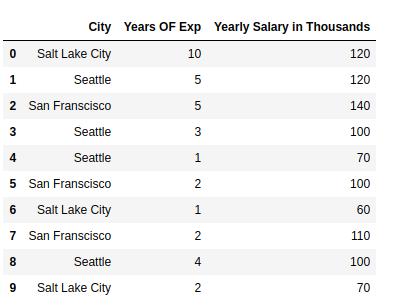
import category_encoders as ce
tenc=ce.TargetEncoder()
df_city=tenc.fit_transform(df['City'],df['Yearly Salary in Thousands'])
df_new = df_city.join(df.drop('City',axis = 1))
df_new