This video explains the technique of Recursive Feature Elimination for feature selection when we have data with lots of features.

Why do we need Feature Elimination?
Often we end up with large datasets with redundant features that need to be cleaned up before making sense of the data. Some of the challenges with redundant features are:
- They take up significant processing power. Lets say we want to train a complex model. The number of parameters of the model is typically dependent on the number of features. So the more features, the more time to train and predict.
- They could consume significant space. Lets say we have a large dataset with hundreds of millions of rows. Having extra columns could add significant overhead leading to out of memory errors during wrangling the data and even model building.
- Redundant features such as collinear features, linearly dependant features lead to problems with solvers and might lead to bad outcomes during training.
Bottomline: It is useful to remove redundant features in many cases.
What is Recursive Feature Elimination or RFE?
Recursive feature elimination is the process of iteratively finding the most relevant features from the parameters of a learnt ML model. The model used for RFE could vary based on the problem at hand and the dataset. Popular models that could be used include Linear Regression, Logistic Regression, Decision Trees, Random Forests and so on.
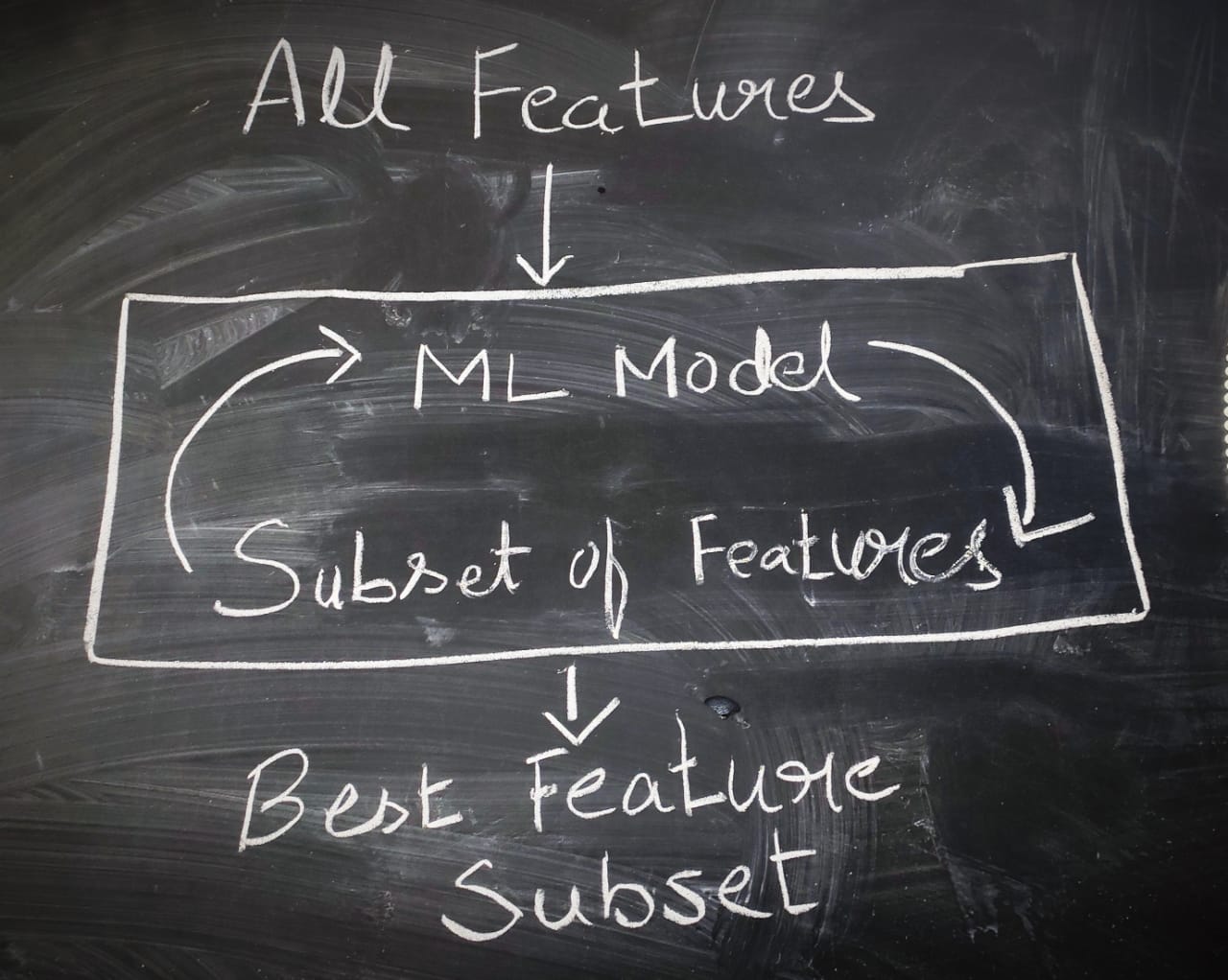
The following block diagram shows the process of iterative feature elimination. We start with all features. Build a model and remove the least important features based on the parameter values from the model. Now rebuild the model with the remaining features. This process continues recursively until no more features or removed, or we have reached the requested number of features.
How can use use Recursive Feature Elimination in Python?
Recursive Feature Elimination or RFE can be readily used in python for feature selection. Checkout the following piece of code to get an idea how RFE can be used.
from sklearn.feature_selection import RFE from sklearn.linear_model import LogisticRegression model = LogisticRegression() rfe = RFE(model, 4) fit = rfe.fit(X, Y) print("Num Features: %s" % (fit.n_features_)) print("Selected Features: %s" % (fit.support_)) print("Feature Ranking: %s" % (fit.ranking_)) >>Num Features: 4 >>Selected Features: [ True True False False False True True False] >>Feature Ranking: [1 2 3 5 6 1 1 4]
For more information, refer to https://scikit-learn.org/stable/modules/generated/sklearn.feature_selection.RFE.html