
This video talks about the Mean Average Precision at K (popularly called the MAP@K) metric that is commonly used for evaluating recommender systems and other ranking related problems.
Why do we need Mean Average Precision@K metric?
Traditional classification metrics such as precision, in the context of recommender systems can be used to see how many of the recommended items are relevant. But precision fails to capture the order in which items are recommended.
Customers have a short attention span – and it is important to check if the right items are being recommended at the top!
For a more detailed post on evaluating recommender systems in general, checkout out this post on evaluation metrics for recommender systems.
How does MAP@K metric work?
The MAP@K metric stands for the Mean Average Precision at K and evaluates the following aspects:
- Are the predicted items relevant?
- Are the most relevant items at the top?
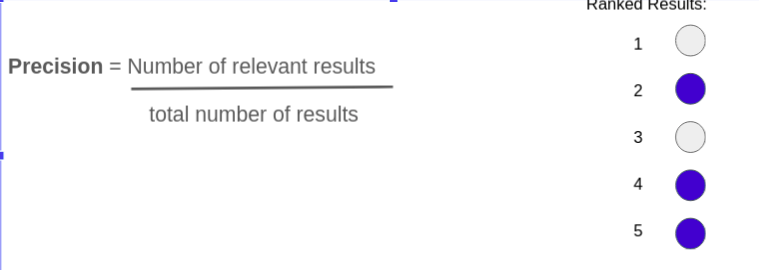
What is Precision?
Precision in the context of a recommender system measures what percent of the recommended items are relevant.
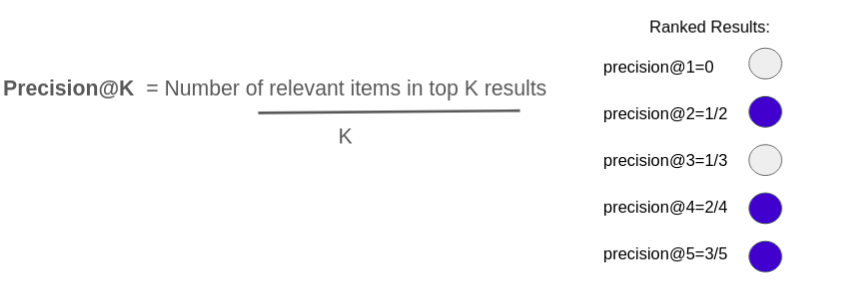
What is precision@K?
Precision@K is the fraction of relevant items in the top K recommended results.
What is Average Precision@K ?
AP@K is the sum of precision@K for different values of K divided by the total number of relevant items in the top K results.

Mean Average Precision@K
The mean average precision@K measures the average precision@K averaged over all queries (for the entire dataset). For instance, lets say a movie recommendation engine shows a list of relevant movies that the user hovers over or not.
The MAP@K metric measures the AP@K for recommendations shown for different users and averages them over all queries in the dataset.
The MAP@K metric is the most commonly used metric for evaluating recommender systems.
Another popular metric that overcomes some of the shortcomings of the MAP@K metric is the NDCG metric – click here for more on NDCG metric for evaluating recommender systems.
Related References for Mean Average Precision
Wikipedia page on metrics based on Average Precision for recommender systems