All of us know random forests, one of the most popular ML models. They are a supervised learning algorithm, used in a wide variety of applications for classification and regression.
Can we use random forests in an unsupervised setting? (where we have no labeled data?)
Isolation forests are a variation of random forests that can be used in an unsupervised setting for anomaly detection.
Recap: What is a anomaly detection? Why is it hard ?
Anomaly detection is a common problem that comes up in many applications such as credit card fraud detection, network intrusion detection, identifying malignancies in the heath care domain and so on.
It is the process of finding the outliers or anomalous points given a dataset. In these applications, usually there are many examples of normal data points, but very few or no examples of anomalous data points. In other words we have mostly examples of a single class and have very few examples of the anomaly class making the classification problem highly imbalanced.
Hence supervised learning techniques such as random forests and SVM are hard to use in this highly imbalanced setting.
Recap: What is a random forest?
The random forest classifier is an ensemble learning technique. It consists of a collection of decision trees, whose outcome is aggregated to come up with a prediction.
Individual decision trees are prone to overfitting. Random Forest is a bagging technique that constructs multiple decision trees by selecting a random subset of data points and features for each tree. Given a subset of the data and featurees, the decision trees themselves are created by partitioning the data feature by feature until each leaf is homogeneous.
What are Isolation forests?
The goal of isolation forests is to “isolate” outliers. The algorithm is built on the premise that anomalous points are easier to isolate tham regular points through random partitioning of data.
The algorithm itself comprises of building a collection of isolation trees(itree) from random subsets of data, and aggregating the anomaly score from each tree to come up with a final anomaly score for a point.
The isolation forest algorithm is explained in detail in the video above. Here is a brief summary.
Given a dataset, the process of building or training an isolation tree involves the following:
- Select a random subset of the data
- Until every point in the dataset is isolated:
- selecting one feature at a time
- Partition the feature at a random point in its range.
As showin the picture below, an interior point requires more partitions to isolate, while an outlier point can be isolated in just a few partitions.

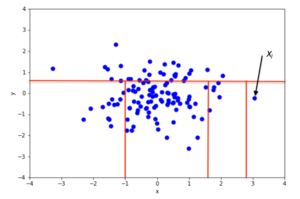
Given a new point, the prediction process involves:
- For Each itree in the forest
- Perform binary search for the new point across the itree, traversing till a leaf
- Compute an anomaly score based on the depth of the path to the leaf
- Aggregate the anomaly score obtained from the individual itrees to come up with an overall anomaly score for the point.
Anamolous points will lead to short paths to leaves, making them easier to isolate, while interior points on an average will have a significantly longer path to the leaf.
Also refer to One-Class-SVM, a variation of SVM in an unsupervised setting for anomaly detection.
References:
- https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.IsolationForest.html
- https://en.wikipedia.org/wiki/Isolation_forest
- Liu, Fei Tony; Ting, Kai Ming; Zhou, Zhi-Hua (December 2008). “Isolation Forest”. 2008 Eighth IEEE International Conference on Data Mining: 413–422. doi:10.1109/ICDM.2008.17. ISBN 978-0-7695-3502-9.