Pandas is super popular for data science tasks. But code written in pandas can often be slow. This article talks about how one can make pandas code faster.
We will walk through a super simple task of adding 1 to every element in the first column of a dataframe and see how different ways of doing this can have an impact on execution time. We have profiled the execution time for each of the techniques to make it easier for you… Here are the experiments tried..

You can access the jupytor-notebook here where you can play with the code directly and draw your own conclusions. Now lets dig into this deeper…
Data and task for sample code in the notebook
We start with some imports – of pandas and numpy. It is also good to set the seed if you want to see the same outcome everytime you run the notebook.
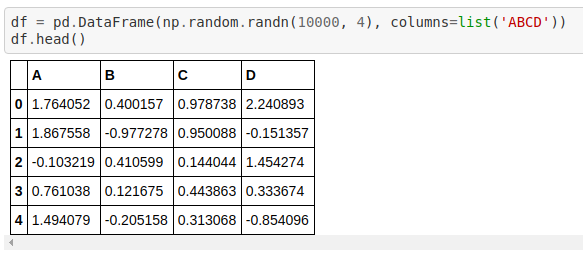
We will use sample data generated randomly as shown above by creating a 10000 row dataframe with 4 columns using the numpy random.randn function.
The task we want to work with is simple: We want to add 1 to every element of the first column of the dataframe
Code with Basic Looping is slow
We can start exploring by doing a basic loop over every row index and accessing the element in the first column of the dataframe as follows. One can then time this task using the tool timeit that shows the average time taken to execute this piece of code.
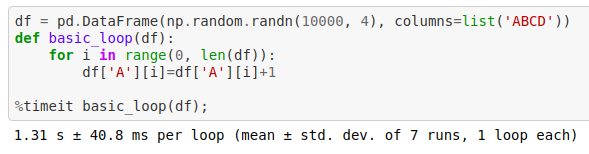 However, as you will see, this turs out to be very inefficient
However, as you will see, this turs out to be very inefficient
Using IterRows to loop over pandas dataframe
Replacing a naive loop with iterating using iterrows leads to some improvement in runtime. We can compare the time taken to run the following code is less (14.2 milli seconds) than the previous time taken for crude looping (1.31 secs). Definitely an improvement.

Using apply to loop over pandas dataframe
A much better way to perform an operation on every row of a pandas dataframe is to use the apply method. In the piece of code below, we are replacing looping explicitly over rows with apply that goes every every row and applies the lambda expression we defined to add 1. 
We see that using apply significantly improves the runtime compared to the previous experiment with iterrows.
Using pandas vectorization to loop faster
There are many operations that pandas supports directly on its columns. And addition of a scalar (like adding 1) is one of them. In the following piece of code, we see how we can directly pass the dataframe column df[‘A’] and add 1 to it. When this is executed a 1 is added to every element of this column.

Using Numpy vectorization to loop over pandas dataframe
Finally, a column of a dataframe is a pandas series. As we know a series internally contains a numpy vector. Operations on numpy vectors are often significantly faster than working with series objects instead since they eliminate a lot of overhead.
How to retrieve the underlying numpy array from a pandas data frame column?
df[‘A’].values retrieves the underlying numpy array. Numpy supports several operations directly on arrays – hence to add 1 to every element of an array, we can simply do col=col+1 on the array.
 We once again see that this turns out to be faster than doing a similar operation on the pandas dataframe column.
We once again see that this turns out to be faster than doing a similar operation on the pandas dataframe column.
Summary: How to make pandas code faster ?
First thing to remember when working with pandas code for scientific/ math computation is to vectorize operations whenever possible instead of looping.
When it is not possible to use the operation directly on the vectorized version of the column, use apply to go over all rows and apply the operation. To add a one (a simple arithmetic operation), we just had to do +1 on the numpy vector. Examples of operations that cannot be directly performed in a vectorized format include non-trivial math operations you might want to apply on elements of the column.
Once again, here is the notebook if you want to play with this code..